Game of Life: my tour of multi-threading and OpenGL
It’s long overdue that I try my hand at writing a multi-threaded program. Being a wanna-be game technology developer, it’s past time for me to learn to use OpenGL for graphics as well. So why not roll both of these learning exercises in to one?
If you’re not familiar with Conways Game of Life, [see the Wikipedia article on it for a quick introduction]. The Game of Life algorithm can be described as a pure function, making it a very good candidate for multi-threading. Additionally, the visual representation of living and dead cells need be little more than different colored squares. Sounds like a good subject to base my exercise on, right?
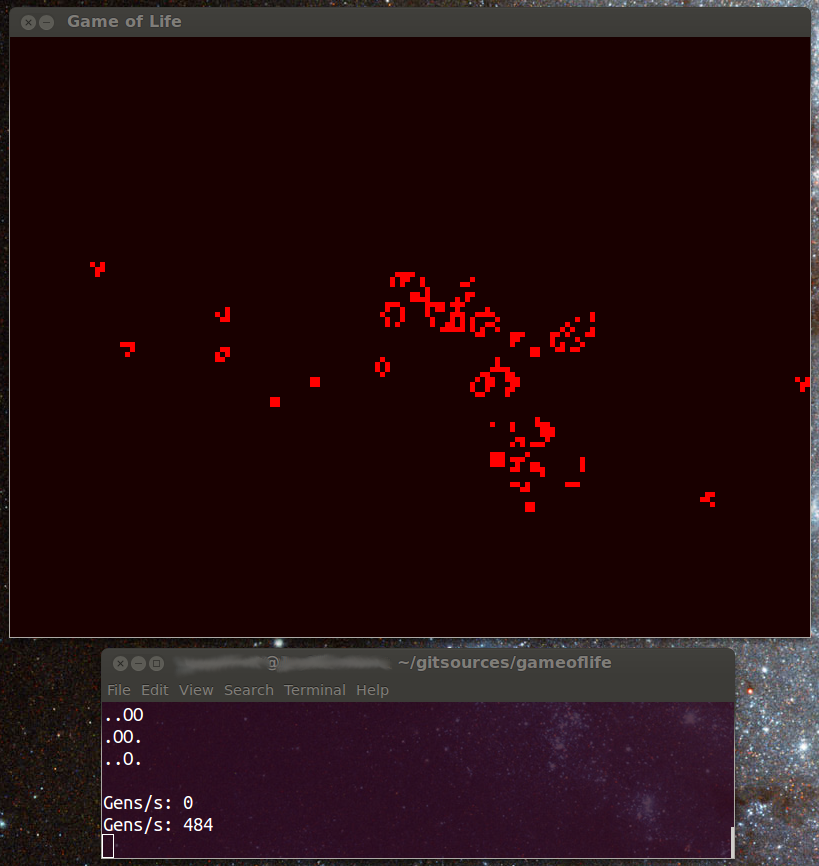
I’ve been working on my simulator for a few weeks now. I’ve made good progress, having graphics with OpenGL working and making use of two threads. Below you can see a screenshot of my program generating from an r-pentomino starting condition.
The threading scheme I’m using right now isn’t optimal, and neither is the algorithm I’m using to process each generation. Currently one thread handles input and renders graphics, while the other runs the Life simulation alone. They run asynchronously, so not every generation is able to be rendered to the screen. The same scheme could be accomplished with a single thread but occasionally the life algorithm would have to wait on a frame to be drawn to the screen, slowing it down. With two threads, the simulation thread only needs to pause momentarily when the graphics thread locks it to make a copy of the cell data. Once it copies the cell data, it unlocks the simulation thread so that it can continue simulating and the graphics thread draws to the screen independently. This is considerably faster. The generation algorithm is a pure-brute force one, simulating every cell of every frame every generation. There’s a lot of room for improvement there, considerably more than would be gained by simply splitting the brute-force method across multiple threads.
I’m currently working on improving the generation algorithm by making use of a technique called “dirty rectangles”. The “dirty rectangles” technique most often applies to graphics, but is perfectly applicable to the Life algorithm as well. The gist of the technique as it applies to graphics is that you make note of which parts of the screen have changed, and then only re-draw those parts of the screen. It’s quite inefficient to re-draw the entire scene if only a small portion of it has changed. It works slightly differently when applied to Life, but the idea is the same. In Life, a cell is guaranteed not to change state if none of its neighbors change state. If no cells in a given area change, why should we bother simulating that area to get the next generation? The next generation will be identical to the one it came from!
My plan for implementing this technique in a thread-friendly way is to break down the Life world in to many discreet blocks (say, 8×8 cells for example). In the very first generation of the simulation, we simulate every block and make note of which blocks actually changed. These will be the “dirty” blocks. If 95% of the blocks did not change in the first generation, we only need to simulate the 5% of blocks that did for the following generation. One important thing to note is that if any of the cells on the edge of a block change, we need to mark the containing block as well as the block adjacent to the changed cell as “dirty” so that they will be simulated in the next generation. If a cell torwards the middle of a block changes, we only need to mark the containing block because the cell that changed can only affect other cells within the same block. Rinse and repeat, ad infinitum.
Now that the overall workload has been broken down in to discreet blocks, the multi-threading becomes easy. At the end of each generation, make a list of all the “dirty” blocks. Divide these blocks as evenly as possible across all threads, and you’re golden. The threads will need to sync-up at the end of each generation to distribute the blocks for the next generation, but hopefully they will all take nearly the same amount of time to complete their work.
That’s the idea anyway. Now I just have to finish writing the code, which you can grab on GitHub. Until next time, happy programming!

